python爬虫小案例—爬取豆瓣帖子下方评论的邮箱
一、思路:
使用request模块请求网页,使用bs4对所获得网页以lxml格式进行解析,在解析得到的结果中查找特定分类的html标签即attrs={'class': 'reply-doc'}),然后对得到的结果进行循环,使用邮箱格式的正则表达式re.search("\w+@\w+.\w+", comment_ele.text, flags=re.A)搜索筛选出评论中留下的邮箱,以及发帖时间。
二、所使用模块
- reque
- bs4
- re
三、遇到的问题及解决方法
request.get()不能直接获取到网页页面,需要加入headers- 一个帖子存在多个页面,查看网页元素发现,每个页面对应一个网址,存放于类为
paginator的div中,那么可以直接获得对应的网址,存放于url_set()集合中,集合可以去除重复的地址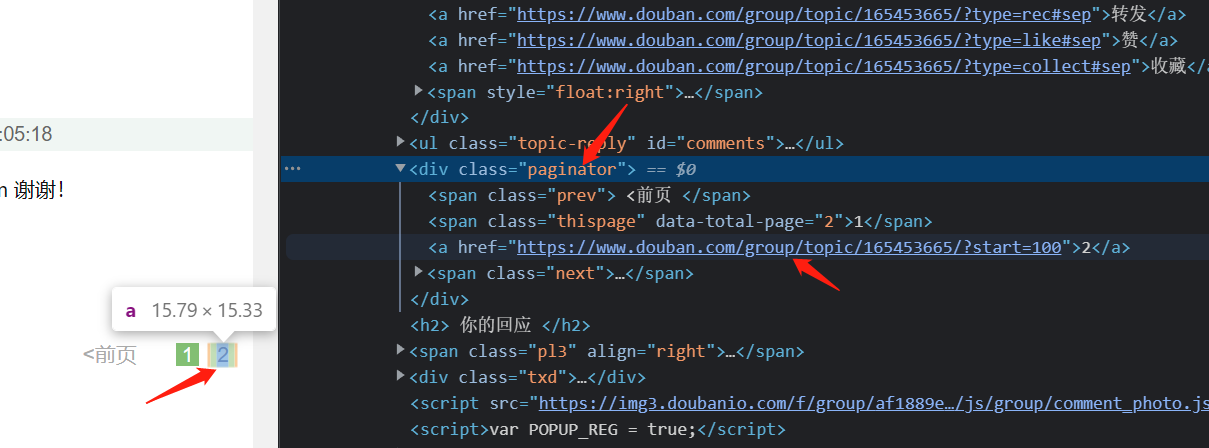
- 如果帖子不存在多个页面,那么会报错,加入一条判断语句
- 邮箱格式的正则表达式
"\w+@\w+.\w+",如果中文直接和邮箱字符紧挨着,那么中文也会被筛选出来,需要加入flags=re.A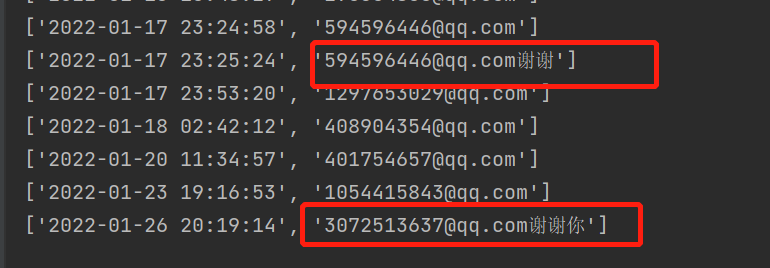
bs4.find()获得的是整个html元素,需要加上.text,获得其文本就行- 正则表达式好处多多,需要学习一下!
四、实现效果
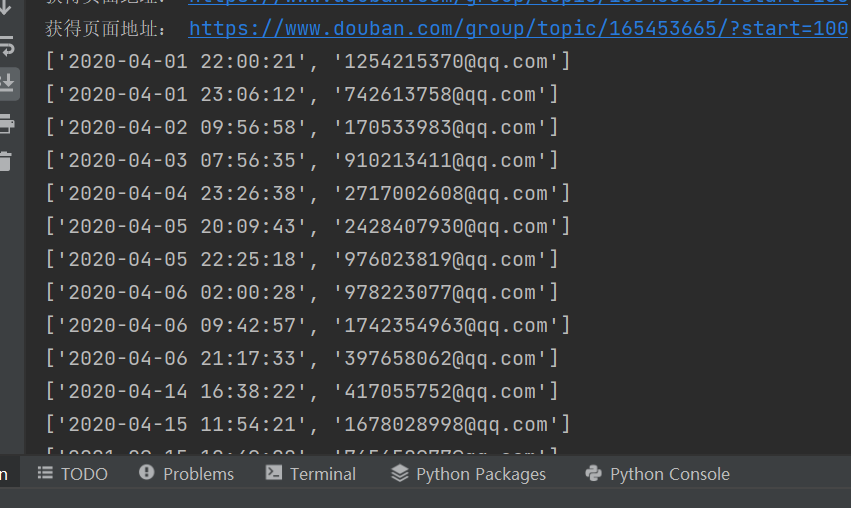
五、代码
import requests
import bs4 # 用来解析所获得的网页
import re
headers = {
'Referer':'https://www.douban.com/group/topic/256821035/?_dtcc=1&_i=6032830F8uHFvK',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="98", "Google Chrome";v="98"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': "Windows",
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36',
} # 浏览器请求网页的header
def page_get(url): # 获得多页面中的各个页面
page_obj = requests.get(url, headers=headers)
bs4_obj = bs4.BeautifulSoup(page_obj.text, 'lxml')
url_set = set() # 存放网页地址,可以去除重复地址
paginator_ele = bs4_obj.find('div', attrs={'class': 'paginator'}) # paginator 页面导航类,先判断是否包含多个分页,不包含分页返回空
if paginator_ele:
for a_ele in paginator_ele.find_all('a'): # 如果包含分页,找到所有a标签,获取页面地址,放入集合url_set
url_set.add(a_ele.attrs.get('href'))
print('获得页面地址:', a_ele.attrs.get('href'))
page_obj_list = [bs4_obj]
for url in url_set:
page_obj = requests.get(url, headers=headers)
page_obj_list.append(page_obj)
return page_obj_list
def email_get(page_obj_list): # 爬取网页中的email
email_list = []
for page in page_obj_list:
bs4_obj = bs4.BeautifulSoup(page.text, 'lxml')
comment_eles = bs4_obj.find_all('div', attrs={'class': 'reply-doc'})
for ele in comment_eles:
comment_ele = ele.find('p', attrs={'class': 'reply-content'})
email_addr = re.search("\w+@\w+.\w+", comment_ele.text, flags=re.A)
if email_addr:
pub_time = ele.find('span', attrs={'class': 'pubtime'})
email_list.append([pub_time.text, email_addr.group()]) # .text获得html元素中的文本
print([pub_time.text, email_addr.group()])
return email_list
page_obj_list = page_get('https://www.douban.com/group/topic/165453665/')
email_list = email_get(page_obj_list)
